
多模态大模型
“视觉编码器对齐到 LLM”的完整流程跑通,并做 ablation(有图 vs 无图)对比
原理
多模态:将其他信号通过模态对齐映射为 tokens,实现 Any-to-Any
发展历程
- CLIP:跨模态对比学习,图像-文本对训练,映射,建立联系
- BLIP-2 & LLaVA:翻译,预训练好的LLM,通过Q - Forme r(BLIP-2) 或 线性投影层 (LLaVA)
- GPT-4o & Gemini 1.5 pro:端到端全模态融合,训练初期视为同等信号
架构范式
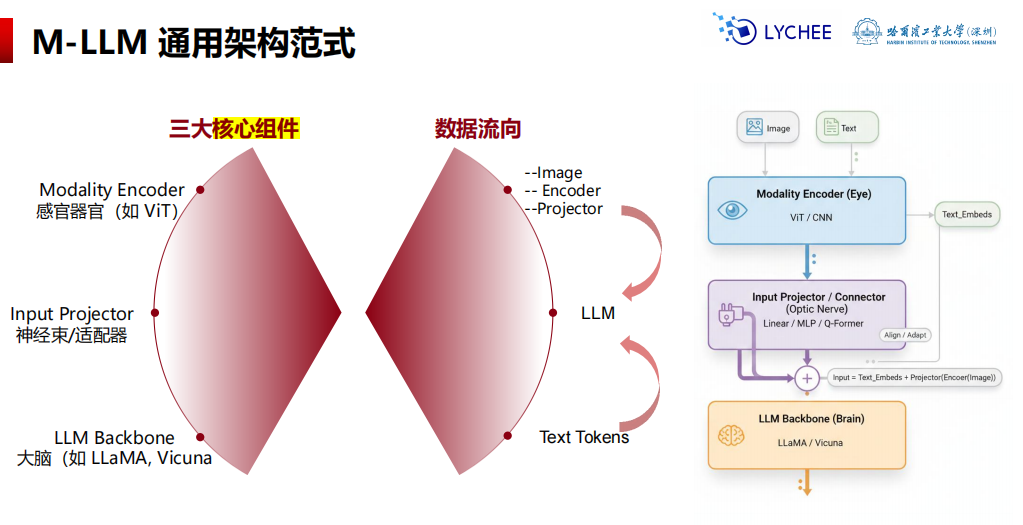
视觉编码器:常用CLIP-ViT
对齐方案:
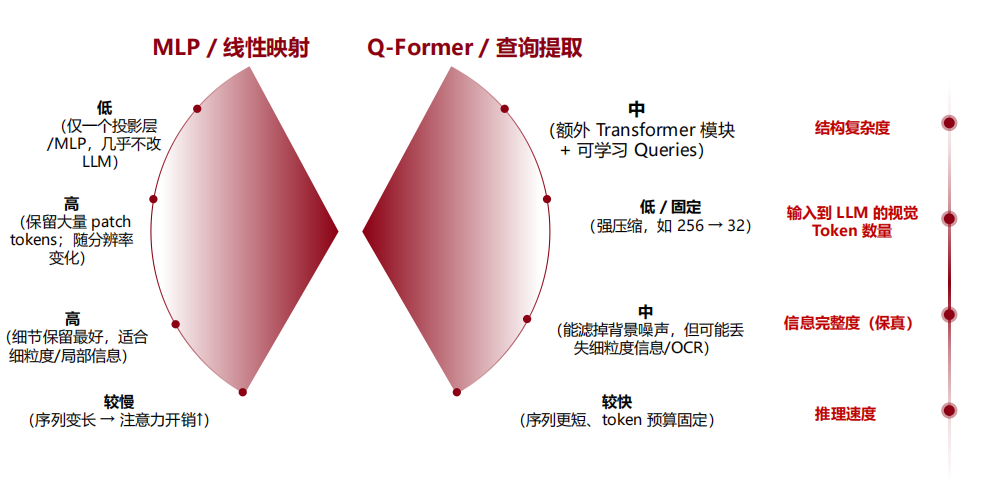
- 线性映射(LLaVA):信息完整,token多,速度慢
- 1)输入形态:视觉编码器(常见是 CLIP-ViT)把图像切成 patch,输出一串向量
- 2)投影(Projector):用一个线性层或两层 MLP 把每个 vi 映射到LLM 的维度di
- 3)拼接进 LLM:把视觉向量当作一段前缀 token,与文本 token 拼在一起
- 查询提取(BLIP-2, InstructBLIP):抓重点,压缩token,加速,但丢失细粒度信息
- 1)输入:密集视觉 tokens,视觉编码器先产生大量 image tokens
- 2)关键组件:可学习 Queries(Q),模型参数本身
- 3)Cross-Attention:用 Q 去读 V,每个 query 关注图像中不同区域/语义(物体、关系、属性),把信息汇总到query 的输出里
- 4)再映射到 LLM,把Q过一层线性/MLP 变到 LLM hidden size,然后作为视觉前缀输入 LLM
特征对齐+指令微调
音频与视频
- Video-LLM:Time-Adapter(时间适配器)的作用,在时间维度做“压缩与对齐”,让模型既保留关键动态信息,又能在 LLM 的上下文长度内工作
- Speech-LLM:ASR(语音转文字)- LLM - TTS(文字转语音)
图文生成
- 工具调用:LLM 当“导演”,扩散模型当“画师”。LLM 写出精确的 Text Prompt(+参数)→ 调用 Stable Diffusion / DALL·E 等图像生成器 → 返回图片
- 原生生成: 把图像离散,再让 LLM 直接预测。先用 VQ-VAE / tokenizer 把图像压缩编码为离散 code,LLM像生成文本一样生成这些 image tokens,然后再解码还原
评估指标
- MMMU:专家级多学科知识
- MathVista:视觉数学推
- POPE:幻觉测试
- 可用性
- 格式稳定性
- 可微调+部署成本
训练对齐层(Projector/Prefix),冻结 CLIP(ViT)和 Qwen(LLM)
- 实验效果:实证明视觉信息成功进入了 LLM 并影响了生成结果(说明多模态机制有效),但模型目前只能粗略理解图片,还没有达到与标准描述(GT Caption)精确对齐的程度。
- with image:更多名词
- LLM only:不稳定
图像 → ViT 得到特征 → Projector 映射到 LLM hidden space → 作为“视觉前缀 token”拼到文本 token 前面 → LLM 继续做因果语言建模。
代码
导包
1 | import os, random |
超参数
NUM_VIS_TOKENS:视觉前缀 token 数(8~32)N_TRAIN:训练样本数(演示用 256~1024 都可以)EPOCHS:训练轮数(2~5)
1 | # ====== tiny demo hyperparams ====== |
数据集(Flickr8k子集)
经典的图像描述数据集,来自 Flickr 的约 8000 张图片及其文字描述。
Flickr8k 是一个包含约 8000 张图片、每张图片配有 5 条人工描述的经典图像描述数据集,经常被用来学习和验证图像描述、多模态模型和视觉语言模型的基本原理。
1 | from datasets import load_dataset |
视觉编码器(ViT/CLIP Vision)
使用clip-vit-base-patch32
1 | from transformers import CLIPVisionModel, CLIPImageProcessor |
语言模型LLM
使用Qwen2.5-0.5B-Instruct
1 | from transformers import AutoTokenizer, AutoModelForCausalLM |
图像 - tokens
输出形状:[B, S, vision_dim],其中 S = 1(CLS) + patches
1 |
|
Prefix-style Projector对齐层
使用prefix(图像特征映射成token)拼在文本token前面,让模型把视觉信息当上下文使用
CLS token是整张图像的全局语义表示
步骤:
- CLS token做图像摘要(ViT或CLIP输出每个patch特征 + CLS token)
- MLP映射到LLM hidden size
- 复制成num个prefix token,序列
- 位置编码
1 | class PrefixProjector(nn.Module): |
batch(ViT_prefix + text)
—> LLM
padding token 不参与 loss
caption:描述说明
1 | PROMPT = "Describe the image in one sentence:" |
训练 projector
- 冻结其他
- 训练
- 使用梯度裁剪
1 | def collate_fn(batch): |
推理
- With image:vis_prefix + prompt
- LLM_only:prompt
- top_p + temperature 采样
- gen_max_new 长度限制
- decode 后保留第一句
vlm:vision-language-model
1 | # 不使用 trans.gen,手写 “prefill + decode” 的 token-by-token 解码流程 |
KV Cache = 模型的“临时记忆”或“草稿纸”
模型把中间计算结果存起来,往后每一次继续更新。
- Q = Query(问题)
- K = Key(索引)
- V = Value(内容)
Cache缓存 KV
单样本展示
GT 是参考caption,看描述是否与文本有关联
1 | ex=val_small[0] |

- 已经学会按 caption 风格续写,但是对齐不稳,出现与图片不相关的胡编。更多学会生成格式,而非准确 grounding。
消融
1 | print("With image:", vlm_greedy_answer(img, "", max_new_tokens=24)) |

With image:输出 图像描述 风格,视觉前缀改变了生成分布,但容易退化为重复模板LLM only:语言先验随意续写的结果