import os os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
离线/集群状态
先在有网的机器把模型下载到某目录(HF cache)。
集群离线时设置:
export HF_HOME=/path/to/hf_cache
export TRANSFORMERS_OFFLINE=1
from_pretrained(MODEL_ID, local_files_only=True)
导包
1 2 3 4 5
import os, re, math, random import torch import pandas as pd from transformers import AutoTokenizer, AutoModelForSeq2SeqLM from transformers import AutoTokenizer, AutoModelForCausalLM
加载模型 + 数据准备
使用Qwen2.5-0.5B-Instruct
prompt模板(3)
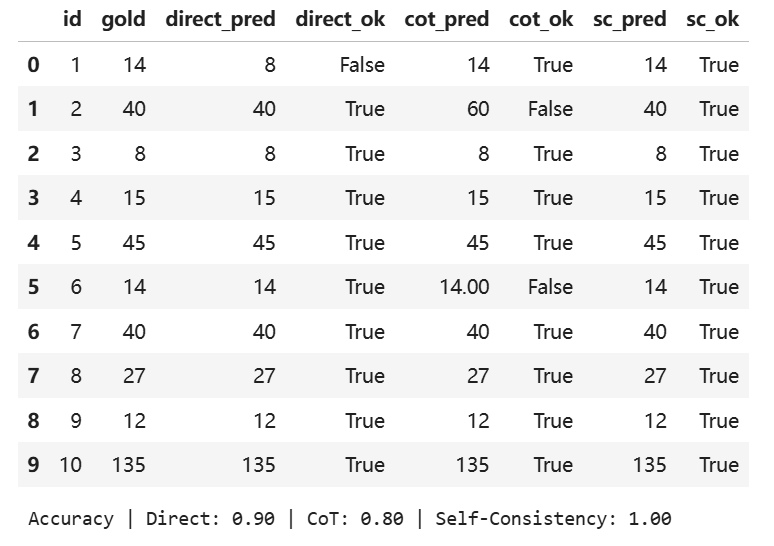
direct answer:最终答案
CoT:逐步推理,中间推理显式化
Self-Consistency:采样多条CoT,多数投票
1 2 3 4 5 6 7 8 9 10 11 12
defprompt_direct(q:str)->str: returnf"""Solve the problem and give only the final answer as a number. Question: {q} Final answer:"""
defprompt_cot(q:str)->str: # 鼓励分布推理+明确 Final answer returnf"""Solve the problem step by step. At the end, write 'Final answer: <number>'. Question: {q} Let's think step by step."""
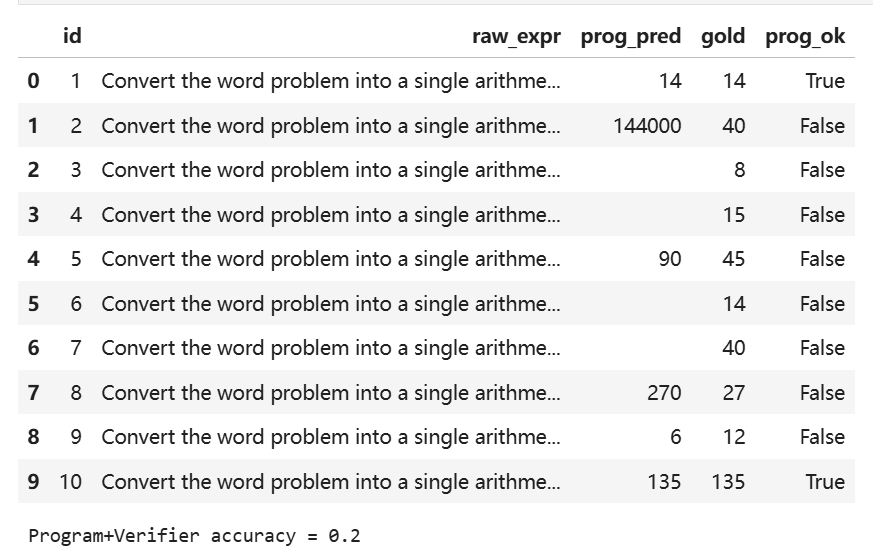
# 问题转换成算术表达式 defprompt_program(q: str) -> str: returnf"""Convert the word problem into a single arithmetic expression using numbers and + - * / parentheses. Return only the expression. Question: {q} Expression:"""
defrun_program_verifier(example): raw_out=generate_text(prompt_program(example["question"]),max_new_tokens=64,do_sample=False)[0].strip() val=safe_eval_arith(raw_out) if val isnotNone: # 判断整数:做四舍五入,并转成字符串 ifabs(val-round(val)) < 1e-6: pred=str(int(round(val))) else: pred=str(val) else: pred="" return raw_out,pred