MoE混合专家模型
用于解决参数规模与计算成本的矛盾:
- Dense(传统模型):参数变大,计算量线性增长
- Sparse(MoE模型):参数量巨大,每次推理只激活其中一小部分
原理
一、MoE 是什么
稀疏激活大模型:总参数极大,但每个 token 只激活Top‑k 个专家,计算量不随参数暴涨。
- 普通 Dense:参数↑→计算 / 显存 / 带宽全↑
- MoE:参数↑→每 token 计算可控
二、结构与位置
- 只替换FFN/MLP,Attention 保持 Dense
- 专家 = 独立 FFN 模块
- 现代 MoE 三件套:
- 共享专家:所有 token 必走,稳通用能力
- 路由专家:按 token 选 Top‑k,做专业化
- 细粒度专家:多而小,分工更细
三、路由 Router(怎么选专家)
- 给 token 打专家分数
- Softmax 转概率
- 选Top‑k
- 选中专家权重重归一化
- 输出加权合并
Top‑1 vs Top‑2
- Top‑1:省计算 / 通信,训练易不稳
- Top‑2:更稳、防塌缩,成本更高
- 经验:训练 Top‑2,推理 Top‑1
四、系统核心:专家并行 EP
- 专家分散在多 GPU
- 必须做all‑to‑all通信(token 发去专家卡→算→收回)
- 拖后腿者 Straggler:最慢卡 / 最堵专家决定 p99 尾延迟
五、计算三步流水线
- Dispatch:token 分桶→跨卡发专家
- Compute:各专家算自己的小 batch
- Combine:结果回传→加权→归位
六、训练三大坑 + 解法
-
负载不均
问题:热门专家挤爆,冷门闲置
解法:Aux LB 损失强制均匀
-
路由塌缩
问题:少数专家被垄断,logits 极端
解法:z‑loss+ 温度 / 噪声
-
容量溢出
问题:专家装不下太多 token
解法:Dropless 块稀疏核(不丢 token)
七、混合并行
- Dense 层(Attention):TP 张量并行
- MoE 层:EP 专家并行+all‑to‑all
- 数据同步:DP/FSDP
- 瓶颈:TP 与 EP 抢带宽
八、推理:Prefill vs Decode
- Prefill:批量处理,吞吐高、通信少
- Decode:逐 token 生成,通信频繁 + 带宽墙 + 尾延迟爆炸(线上最难)
九、推理延迟来源
- Router 额外计算
- 权重读取慢(显存带宽瓶颈)
- all‑to‑all 跨卡通信
- 专家负载不均
十、线上优化
- 动态 batch、专家分桶、负载感知路由
- 权重全放 GPU
- 量化 + KV 压缩(减显存 / 带宽)
十一、三句终极总结
- 架构:稀疏激活扩能力不扩计算,共享 + 路由 + 细粒度专家
- 系统:TP+EP 混合,通信与尾延迟决定性能
- 线上:Decode 优先优化带宽、all‑to‑all、p99 延迟
代码
- **Qwen2.5-0.5B **作为基座
- 前馈神经网络(FFN/MLP)挖掉,换成
MoE Layer - 实现
Top-2路由和负载均衡损失计算 - 一次前向传播和反向传播,
Token分发
关键代码:
- 门控网络 (Gate):
self.gate = nn.Linear(...)。它就像一个“交通指挥官”,根据输入 Token 的特征,计算它去往每个专家的“推荐分数”。 - 稀疏路由 (Top-K Routing):
torch.topk(gate_logits, ...)。这是 MoE 效率高的关键。虽然我们有 4 个专家,但每个 Token 只计算前 2 个分数最高的专家。剩下的专家处于“休眠”状态,不消耗算力。 - 辅助损失 (Aux Loss): 用于防止**“路由塌缩” (Routing Collapse)**。如果没有这个 Loss,Router 很可能会“偷懒”,把所有任务都丢给同一个专家,导致负载极度不均衡。
导包
1 | import torch |
MoE Layer 代替前馈神经网络FFN
- 专家集合:
self.experts = nn.ModuleList(...):创建4个结构完全相同的MLP,各自处理不同类型的知识。 - 门控:
self.gate = nn.Linear(...):全连接层,给每个token打分,torch.topk(gate_logits, ...),实现Top-2路由,也是MoE的稀疏激活。 - 辅助损失:计算了
aux_loss(负载方差),不均衡 loss变大,迫使反向传播进行调整
1 | class MoELayer(nn.Module): |
加载基座模型
使用模型Qwen2.5-0.5B
- 对配置微调:Qwen2.5 默认头数是 14。如果不修改,计算
512 / 14会得到小数,导致 Transformers 库报错(维度无法对齐) - 头数改为16
- from_config 表示是未经训练的空壳模型(权重随机)
1 | # 修改配置 |
模型架构 model.model.layers[2].mlp
1 | Qwen2MLP( |
模型手术:Dense转为 MoE
- 定位:
model.model.layers[2].mlp,是一个稠密网络,任何token经过都要计算所有参数 - 切除与移植 moe_layer 覆盖 mlp
model.model.layers[target_layer_index].mlp = moe_layer
打印模型结构:
- Before:
Qwen2MLP(Gate+Up+Down Proj) - After:
MoELayer(包含 Experts 列表和 Gate 路由)
经过第二层的Token都会被强制执行路由,分给不同专家
1 | # 设置 MoE 参数 |
模型架构 model.model.layers[target_layer_index].mlp | [Layer2]
1 | MoELayer( |
前向传播与数据观测
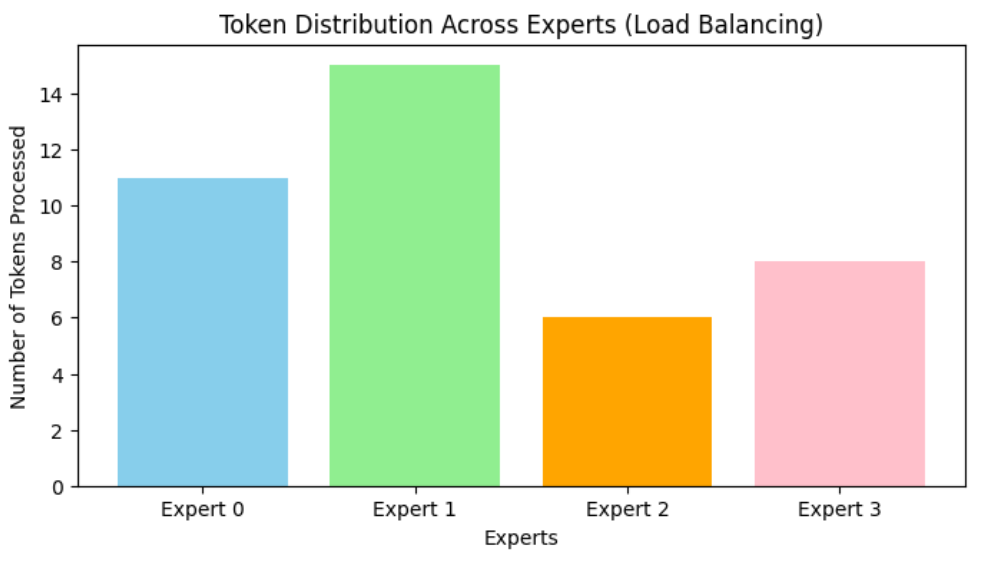
注意专家负载分布
Aux Loss量化不平衡成都,是Router的惩罚项。反向传播时,优化器会降低该loss,迫使均匀
1 | # Batch Size=2,Seq_len=10 |
- 语言模型交叉熵 Loss: 12.0706
- MoE 辅助损失 (Aux Loss): 1.0078
- 专家负载分布: [11.0, 15.0, 6.0, 8.0]
反向传播
total_loss = lm_loss + 0.01 * aux_loss
- lm_loss: 让模型学会预测下一个字(说话通顺)
- aux_loss: 让模型学会均衡分配任务(团队协作)
- 0.01: 这是一个超参数(系数)。我们通常希望模型优先学好语言(权重大),其次兼顾负载均衡(权重小)
1 | # 训练循环中,每次 forward 后都要重新获取 aux_loss |
总 Loss: 12.0807
路由分布可视化