
RAG检索增强生成
是将信息检索与文本生成深度融合的架构
原理
- 稀疏检索:关键词匹配与词频统计
- 稠密检索:词义嵌入向量的相似度匹配
- 嵌入编码:文本转为低维稠密向量
- 索引构建:存入向量数据库
- 相似度检索:余弦相似度,召回Top_k
- 编码融合生成:问题与检索文档一同输入编码器
- Prompt拼接生成:将检索片段拼接在用户问题Prompt中
整体架构

挑战
- 检索准确性问题
- 稀疏+稠密混合检索
- 重排序模块
- 查询扩展与改写
- 多文档融合难度
- 系统效率瓶颈
- 知识时效性与更新
- 可信度与可追溯性
- 生成、校验
- 多源验证、置信度评分
代码
导包
1 | import numpy as np, torch |
构建知识库
共六条:
- id
- text
文本切块 chunking
词窗口 + overlap(重叠)
1 | def chunk_text(text,chunk_size=24,overlap=6): |
检索器
1 | # 1.向量化器 |
doc_peft: 0.2871094019135437doc_kvcache: 0.0doc_rag: 0.0
加载生成模型
使用flan-t5-small
- tok
- model
- model.eval()
RAG生成函数
1 | def rag_prompt(q,hits): |
基线
无检索直接回答
1 | def direct_answer(q): |
- direct = retrieval is useful in RAG.
- rag = improving factuality and traceability
- doc_rag:0.23400230699614644
- doc_kvcache:0.0
- doc_moe:0.0
评测集
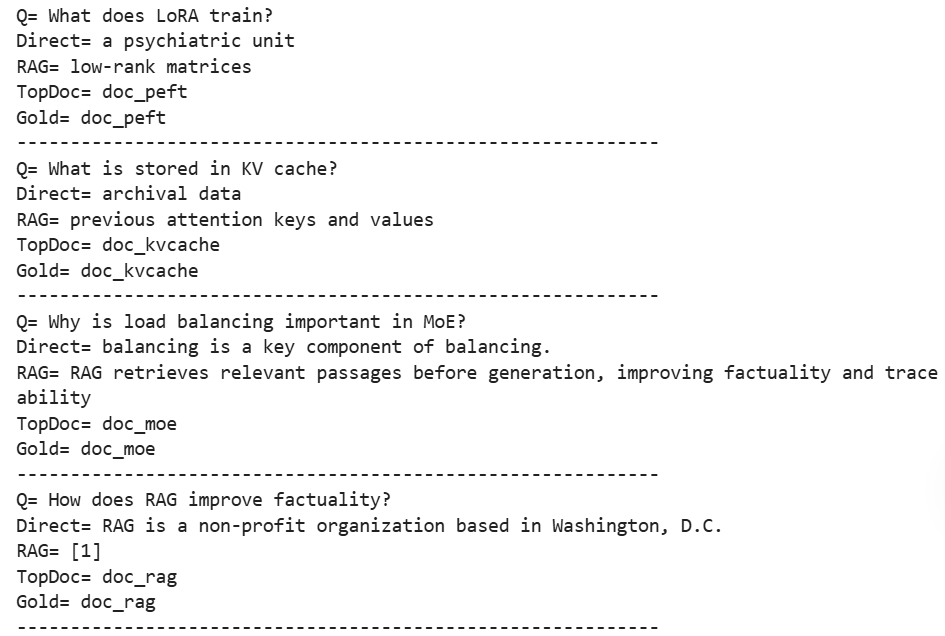
检索指标
命中率:Hit@k,命中则+1
1 | if x['gold'] in doc_ids: hit += 1 |
可解释证明
打印出分数和文本