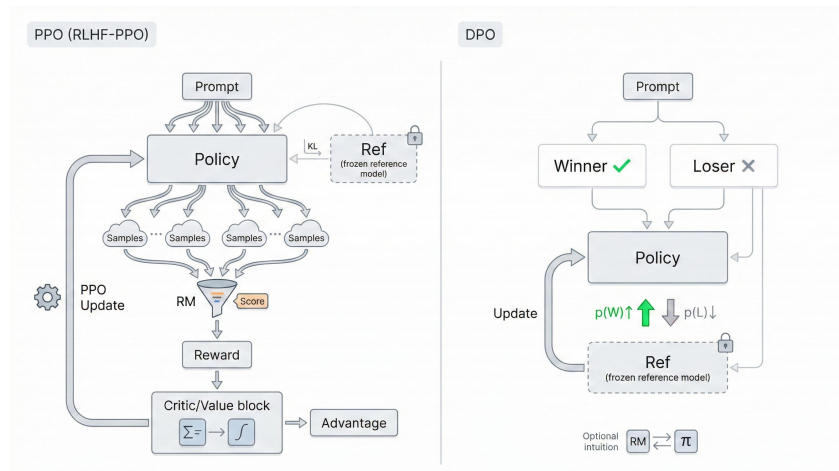
PPO 算法、DPO 原理
风险:
幻觉
有害内容(毒性、歧视)
奖励黑客:找漏洞提升RM,编造废话和拒绝回答
阶段2奖励:
阶段3RL:
PPO 算法
要求:
调参数,提高RM
近端,小步快跑,限制每次更新的幅度
DPO (直接偏好优化)
要求:
优点:
缺点:
Banana任务——受限生成对齐SFT :收集成千上万条人工编写的对话数据进行微调RL :写出规则来“评分”,模型自己学习“怎么做”
“受限生成”任务:
A:以Sure:开头
B:以banana结尾
C:回答简短(对冗长输出惩罚)
Policy:QwenReward:Python函数,格式正确+1.0,否则不得分
1 2 3 4 import torchfrom transformers import AutoTokenizer, AutoModelForCausalLMfrom datasets import Datasetfrom trl import RLOOConfig, RLOOTrainer
直接调用transformers
1 2 3 4 5 6 7 8 9 10 11 12 model_path = "./models/Qwen2.5-0.5B-Instruct" tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True ) model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True ).to(device) if tokenizer.pad_token is None : tokenizer.pad_token=tokenizer.eos_token tokenizer.padding_side="left"
使用 Chat Template
因为,现代模型必须用 user/assistant 的对话格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def apply_chat_template (text ): return tokenizer.apply_chat_template( [{"role" :"user" ,"content" :text}], tokenize=False , add_generation_prompt=True ) formatted_prompts=[apply_chat_template(p) for p in raw_prompts] train_ds=Dataset.from_dict({"prompt" :formatted_prompts*5 })
奖励和惩罚
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def _extract_text (completion ): """提取生成的纯文本内容""" if isinstance (completion,list ) and len (completion)>0 : return completion[0 ].get("content" ,"" ) if isinstance (completion[0 ],dict ) else completion[0 ] return str (completion) def reward_format_banana (completions,**kwargs ): rewards=[] for c in completions: t=_extract_text(c).strip() score=0.0 if t.startswith("Sure:" ): score+=1.0 clean_text=t.rstrip(".,!?:;\"'" ) if clean_text.lower().endswith("banana" ): score+=1.0 if "banana" not in t.lower(): score-=0.5 length_penalty=0.005 *len (t.split()) rewards.append(score-length_penalty) return rewards
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 """ 验证函数 """ @torch.no_grad() def evaluate_model (header="Current Status" ): print (f"\n=== {header} ===" ) model.eval () success_count=0 test_prompts=formatted_prompts[:3 ] for p_text in test_prompts: inputs=tokenizer(p_text,return_tensors="pt" ).to(device) out=model.generate( **inputs, max_new_tokens=32 , do_sample=True , temperature=0.7 , pad_token_id=tokenizer.eos_token_id ) full_text=tokenizer.decode(out[0 ],skip_special_tokens=True ) res=full_text.split("assistant\n" )[-1 ].strip() if (len (res)>len (p_text)): pass clean_res=res.rstrip(".,!?:;\"'" ) is_success=res.startswith("Sure:" ) and clean_res.lower().endswith("banana" ) if is_success: success_count+=1 print (f"Output: {res} " ) print (f"Result: {'✅ Success' if is_success else '❌ Fail' } " ) print ("-" * 10 ) print (f"Success Rate: {success_count} /3" ) model.train() evaluate_model("Before Training" )
以上还没有训练前的前期配置和效果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 """ 配置RLOO训练器 """ args = RLOOConfig( output_dir="./rloo_qwen_banana" , per_device_train_batch_size=2 , gradient_accumulation_steps=2 , learning_rate=1e-5 , max_steps=60 , logging_steps=10 , max_completion_length=64 , num_generations=4 , temperature=0.9 , ) trainer = RLOOTrainer( model=model, args=args, train_dataset=train_ds, reward_funcs=reward_format_banana, processing_class=tokenizer, ) trainer.train() evaluate_model("After Training" )
温度越高,越随机有创造性;温度越低,越稳定确定。
现代 RLHF (基于人类反馈的强化学习)的核心领域:Model-based Reward(基于模型的奖励) 。
训练一个“极度乐观”的 AI 助手。无论用户输入什么内容(即使是枯燥的定义或中性问题),模型都必须学会用极度积极、热情、充满正能量的语气来回答。
在上一关,我们的奖励函数是一个“白盒”规则(检查是否以 Banana 结尾);而在这一关,我们的奖励函数变成了一个“黑盒”模型(一个预训练好的 BERT 情感分析模型)。
他们会先训练一个 Reward Model 来模仿人类的喜好,然后用这个 Reward Model 去通过强化学习优化生成模型。
1 2 3 4 import torchfrom transformers import AutoTokenizer, AutoModelForCausalLM,pipelinefrom trl import RLOOConfig,RLOOTrainerfrom datasets import Dataset
主模型
奖励模型
1 2 3 4 5 6 7 8 9 10 11 12 from transformers import pipelinesentiment_pipe = pipeline( "sentiment-analysis" , model="./models/bert_sentiment" , tokenizer="./models/bert_sentiment" , device=device )
同上面,不赘述。这里复制10。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def reward_positive_sentiment (completions,**kwargs ): rewards=[] texts=[] for c in completions: if isinstance (c,list ): text=c[0 ]['content' ] else : text=str (c) texts.append(text[-512 :]) results=sentiment_pipe(texts) for res in results: score=res['score' ] label=res['label' ] if label=='POSITIVE' : rewards.append(score*2.0 ) else : rewards.append(-score) return rewards
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @torch.no_grad() def evaluate_model (header="Current Status" ): print (f"\n--- {header} ---" ) model.eval () test_prompts=formatted_prompts[:3 ] for p_text in test_prompts: inputs=tokenizer(p_text,return_tensors="pt" ).to(device) out=model.generate(**inputs,max_new_tokens=50 ,do_sample=True ,temperature=0.7 ) res=tokenizer.decode(out[0 ],skip_special_tokens=True ).split("assistant\n" )[-1 ].strip() score_dict=sentiment_pipe(res[:512 ])[0 ] print (f"Output: {res} " ) print (f"Sentiment: {score_dict['label' ]} ({score_dict['score' ]:.4 f} )" ) print ("-" * 10 ) model.train()
以上还没有训练前的前期配置和效果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 args=RLOOConfig( output_dir="./rloo_qwen_sentiment" , per_device_train_batch_size=4 , gradient_accumulation_steps=1 , learning_rate=2e-5 , max_steps=80 , logging_steps=10 , max_completion_length=64 , num_generations=4 , temperature=1.0 ) trainer = RLOOTrainer( model=model, args=args, train_dataset=train_ds, reward_funcs=reward_positive_sentiment, processing_class=tokenizer, ) print ("Before Training:" )evaluate_model("Before" ) trainer.train() print ("After Training:" )evaluate_model("After" )