
模型水印与防滥用
原理
攻击手段
- 复述:使用另一种生成模型进行改写和润色,改变token分布与相邻关系
- 插入/删除:少量编辑,造成链条错位,使得token的种子与绿/红名单分配发生偏移
其他安全手段
- 指纹技术:记录模型生成时的参数特质(留下可追溯的运行痕迹)
记录与这次生成绑定的参数特征/元数据(例如模型版本、解码设置、随机种子、调用方ID、时间戳,或对输出做哈希签名),形成一条“指纹记录”
- C2PA协议:打上数字签名(一份内容凭证:数字签名+元数据清单,来源说明)
包含生成/拍摄工具、发布者标识、时间、以及关键编辑步骤的记录,形成一条“内容履历”
- 红队测试:发布前找专家攻击模型、挖掘漏洞
系统性设计高风险提示(越狱、提示注入、诱导泄露、仇恨/暴力/违法内容等),记录模型在不同场景下的失败模式与触发条件。
代码过程
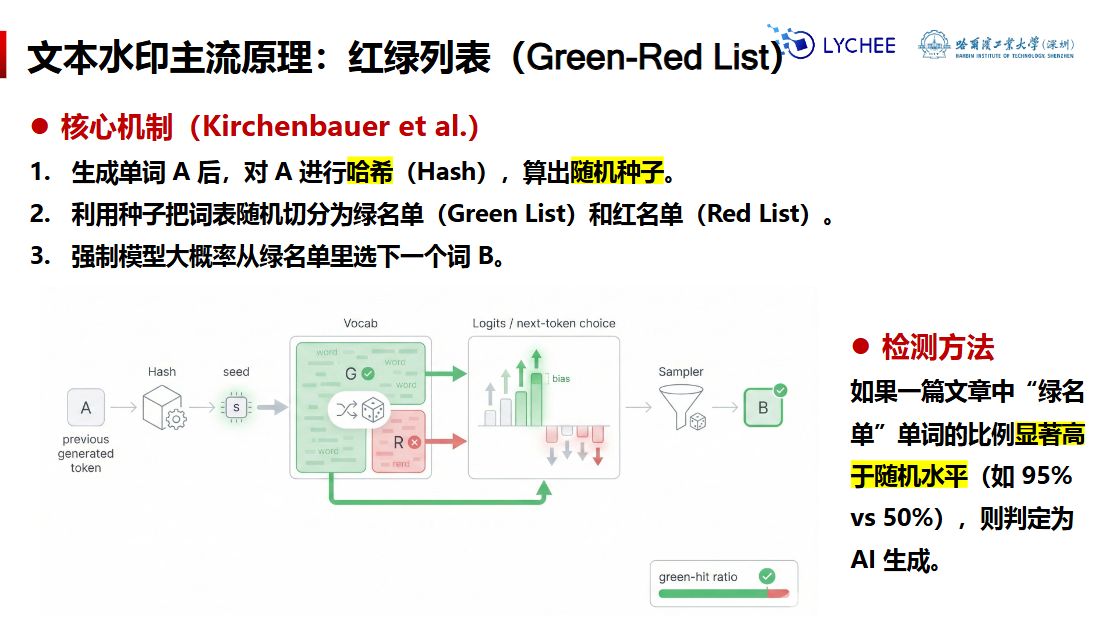
核心原理采用经典的 Greenlist/Redlist 词表分割水印(Kirchenbauer et al., 2023 的思路):
- 嵌入(embed):每步解码用密钥 + 上文生成一个“绿色 token 集合”,对绿色 token 的 logits 加偏置
δ(delta)。 - 检测(detect):复现同样的绿色集合,统计绿色命中率是否显著高于期望
γ(gamma),用 z-score (显著性)做统计检验。
硬水印 = 强制只许用某些词,不许用另一些(像 “黑名单”,碰都不能碰)
- 缺点
- 低熵句子会崩(比如固定搭配、代码、名言)例:“Barack Obama”,模型必须接 Obama,但 Obama 被分到红词,就会生成奇怪的话。
- 文本质量会下降。
软水印 = 悄悄偏爱某些词,不禁止,但更爱选(像 “加分”,不强迫,但更容易被选中)
- 步骤
同样随机分 绿词 / 红词
绿词的概率悄悄提高一点(加个 δ)
模型还是按概率选词,不禁止任何词,只是更爱选绿词
调包
1 | import os, math, hashlib, random |
选择类型
1 | DEVICE = "cuda" if torch.cuda.is_available() else "cpu" |
加载模型
1 | # 加载模型 |
数据 PROMPTS
加水印
核心:PRF生成绿色集合,logits偏置(delta)
- gamma:绿色占比
- delta:对绿色token logits的偏置强度,水印强度(增加概率)
- context_width:生成绿色集合使用的上文token数,越大越上下文相关
1 | """ |
逐个token生成进行解码
1 | # 逐 token解码 |
检验
7.1 检测统计量
对生成序列 gen_ids(长度 n):
- 对每个位置 i:根据密钥 + 上文复现该步 seed
- 判断该 token 是否“绿色”
- 统计命中数
k
7.2 z-score(单比例检验的常见形式)
- 期望命中率是
γ,所以期望命中数nγ - 二项分布的标准差
sqrt(nγ(1-γ))
z值是偏差/标准差
z = (k - nγ) / sqrt(nγ(1-γ))
观察到的结果和理论概率差异显著
|z| > 1.96 → p < 0.05(常用显著性水平),说明偏差可能不是随机的。
z越大:绿色 token 比随机情况“多很多” → 更像有水印n越小:统计不稳 → z 值很难大到超过阈值
1 | """ |
结果比对
如果希望几乎全部detected=True
- 增大max_new_tokens(n变大)
- 增大wm_delta(水印更强)
- 降低z(判断宽松)
1 | # wm配置 |

- plain:没有加水印,z值接近0
- wm:加了水印,z值更大
- detected:判断是否加了水印
- 一般如果加了水印,证明是ai生成,反之不是
分析
-
FP(false positive):plain 被判为有水印的次数(越低越好)
-
TP(true positive):wm 被判为有水印的次数(越高越好)
-
阈值高,误报低,漏报多
-
阈值低,检出高,误报高
选取短和长的文本分别进行对比
1 | # 找到 n很小的样本 |
分析

攻击/破坏:截断与噪声
水印不是万能的:
- 截断:把文本变短,n会下降
- 噪声替换:改写/编辑破坏绿色命中规律
破坏方式:
- 截断到40%
- 随机替换10%token
1 | def truncate_ids(gen_ids,keep_ratio=0.4): |
分析
1 | CLEAN z=2.53 n=23 |
其他参数
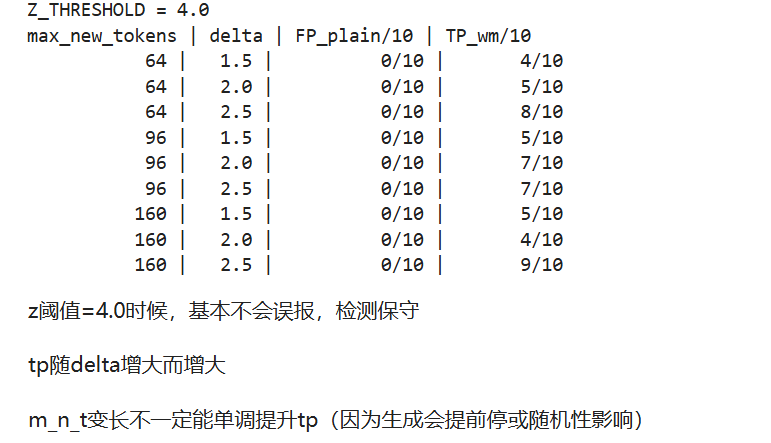
delta和文本长度对检出率的影响
目标:清楚这些“可控旋钮”:
WM_DELTA↑ → 水印更强(TP ↑,可能影响流畅度)max_new_tokens↑ → 样本 n 更大(TP ↑,统计更稳)Z_THRESHOLD↓ → 判定更宽松(TP ↑,FP 可能 ↑)- TP(true positive):预测对了的样本
- FP(false postive):误判为正样本的负样本
采用控制
1 | # 固定 gamma,扫 delta和 m_n_t |
分析
其他
-
密钥(WM_KEY)要保密:
- 服务端持有密钥;检测端在需要溯源时调用(或授权第三方检测)。
-
阈值是策略选择:
- 高阈值:几乎不误报,但可能漏掉短文本/被编辑文本。
- 低阈值:更敏感,但可能出现误报,需要配合更多证据。
-
攻击/鲁棒性:
- 截断、改写、翻译、同义替换都会削弱检测。
- 实际系统要做更系统的对抗评估,并搭配其它治理手段。