
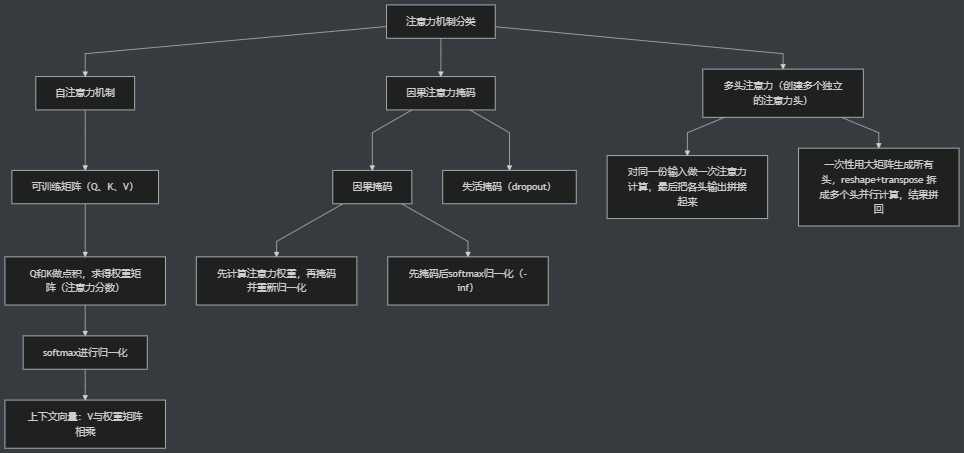
注意力机制
注意力机制
注意力机制解决的问题,对比:
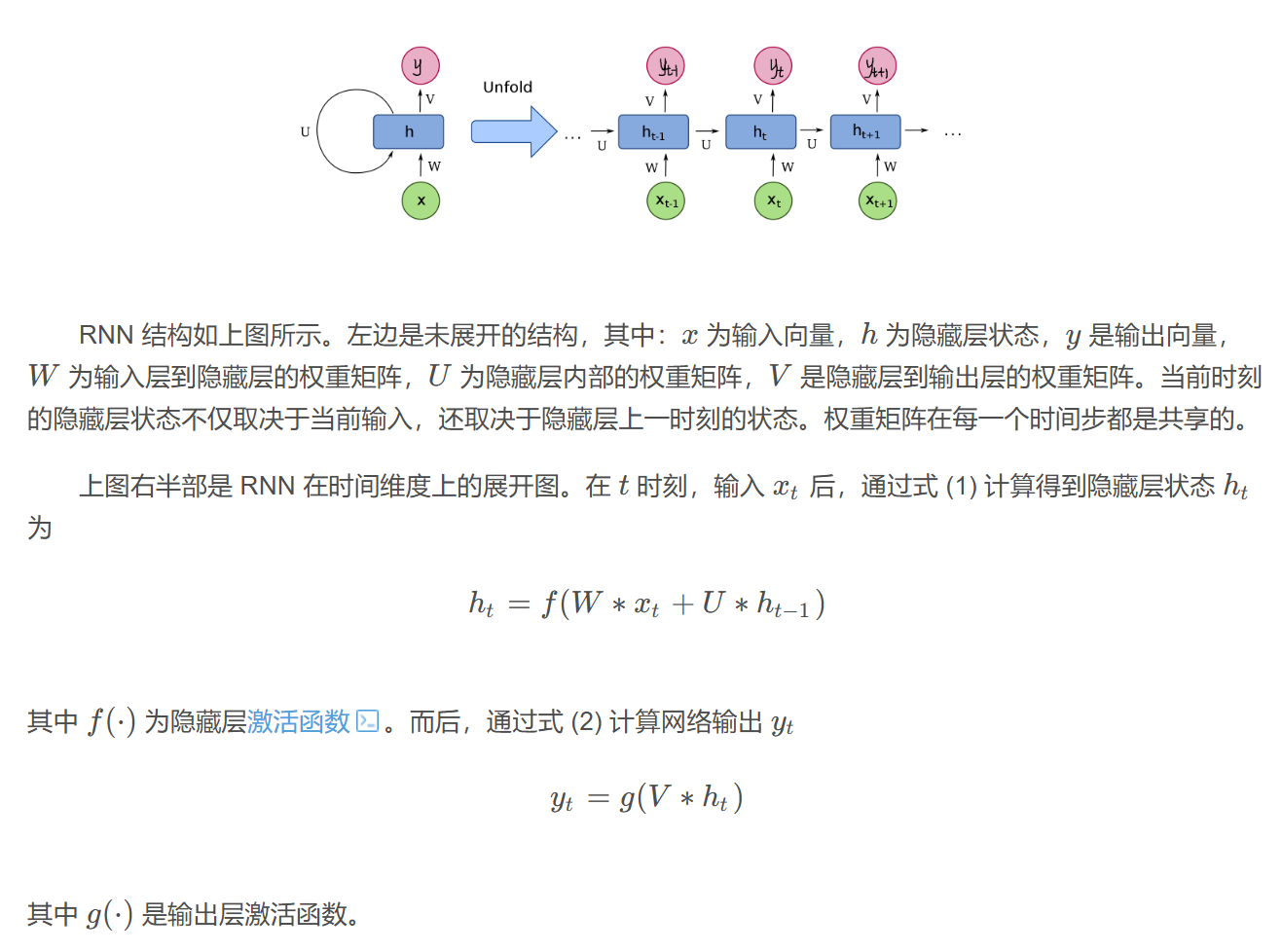
RNN
- 按顺序逐词的方式处理文本
- 将输入压缩为中间状态,但容易遗忘。依赖该中间状态输入
token容易丢失细节,要求不断会看完整输入(遗忘)
自注意力机制
- 访问全部输入状态的历史信息
- 回看整个输入
- 有选择回看(权重)
点积
计算点积:torch.dot(input_query, input_1)
对dot进行展开写:
1 | # enumerate:给每个元素自动编号 |
点积与余弦相似度区别
点积:相关性的“原始分数”,关键取决于夹角(很强+很像)
- 方向
- 长度
余弦相似度:去掉长度影响后的“纯方向相似度”(很像,语义检索常用)
- 只看方向
对所有进行点积
1 | """ |
1 | """ |
归一化
注意力分数转换为注意力权重(即可解释的概率分布)
方法1:简单归一化
1 | attn_weights_2_tmp=attn_score_2/attn_score_2.sum() |
方法2:softmax归一化
实际实现使用这个,会更稳定
1 | def softmax_naive(x): |
简单和softmax区别
softmax:把一组任意实数,转换成一组概率值
普通归一化:
- 可能有负数
- 区分度不够:指数可以放大差异
Attention里面使用softmax:
上下文向量
注意力分数矩阵与x相乘
1 | all_context_vecs=attn_weights @ inputs |
汇总,简化版自注意力模块
1 | attn_scores=inputs @ inputs.T |
实际所用自注意力模块
实际中,不会直接彼此点积,通过三组可训练矩阵
生成query,key,value
query,key得到注意力分数
归一化权重
对value加权求和 --> 上下文向量
方法1:Parameter矩阵
1 | # 推广计算所有的,上述封装到自注意力模块 |
方法2:PyTorch层线性
PyTorch线性层,包含一个可训练的权重矩阵+bias
初始化更合理:
初始化时就考虑输入输出维度的尺度,使参数的初始分布与层的尺寸相匹配
采用Kaiming Uniform 初始化
1 | import torch.nn as nn |
权重服从均匀分布:
其中:
比如:
nn.Linear(4, 3)
那么:
所以范围就是:
作用:
- 防止梯度爆炸
- 防止梯度消失
因果注意力掩码 mask
防止模型预测时,看到后面的未来词,提前拿到答案。
因果掩码
方法1:先计算注意力权重后归一化
1 | """ |
方法2:尚未归一化时先掩码,再softmax
1 | """ |
失活掩码
1 | """ |
多批次
1 | # 考虑常见训练场景:一次同时处理多条输入(批次 batch) |
汇总,因果注意力机制
使用了buffer
1 | import torch.nn as nn |
掩码放在__init__里提前生成,是为了避免在每次forward时重复创建同一份矩阵。因果掩码只与最大上下文长度context_length 有关,本身不需要随着输入或训练动态变化,因此在初始化阶段生成一次即可。前向计算时,输入序列的实际长度可能是num_tokens(可能小于context_length),所以代码用self.mask[:num_tokens, :num_tokens] 截取出与当前注意力分数矩阵同样大小的那一块掩码,既保证尺寸对齐,也避免多余计算。
多头注意力机制
并行运行多个注意力头,让模型从不同视角同时观察同一段文本。eg.更关注语法结构、另一个head更关注情绪预期等。这些 head 各自输出一份上下文表示,最后会被拼接并再做一次整合。
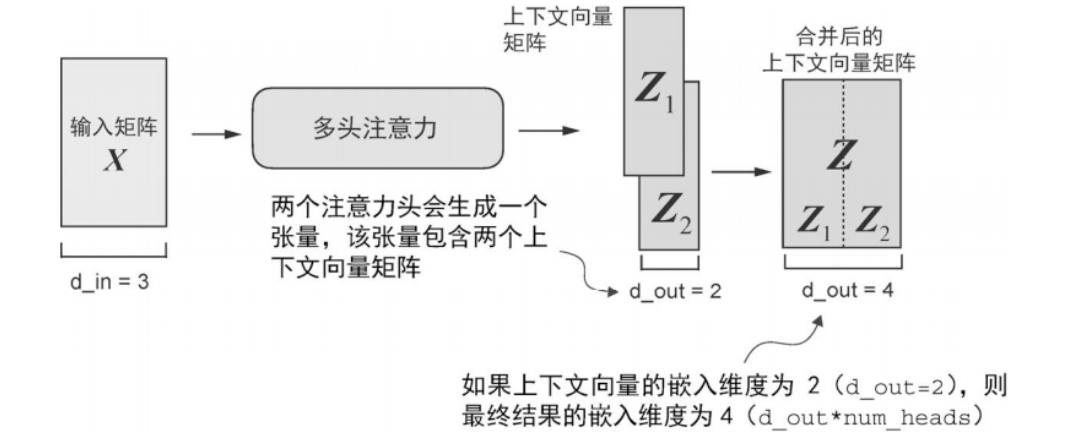
并行使用多个自注意力头,提取不同类型的信息
最后把张量在最后一维拼接起来
- 注意力头的数量是可设置的超参数,初始化所需数量的注意力头
方法1:堆叠多个注意力头,顺序执行
1 | """ |
方法2:一次性生成,再拆分
1 | """ |