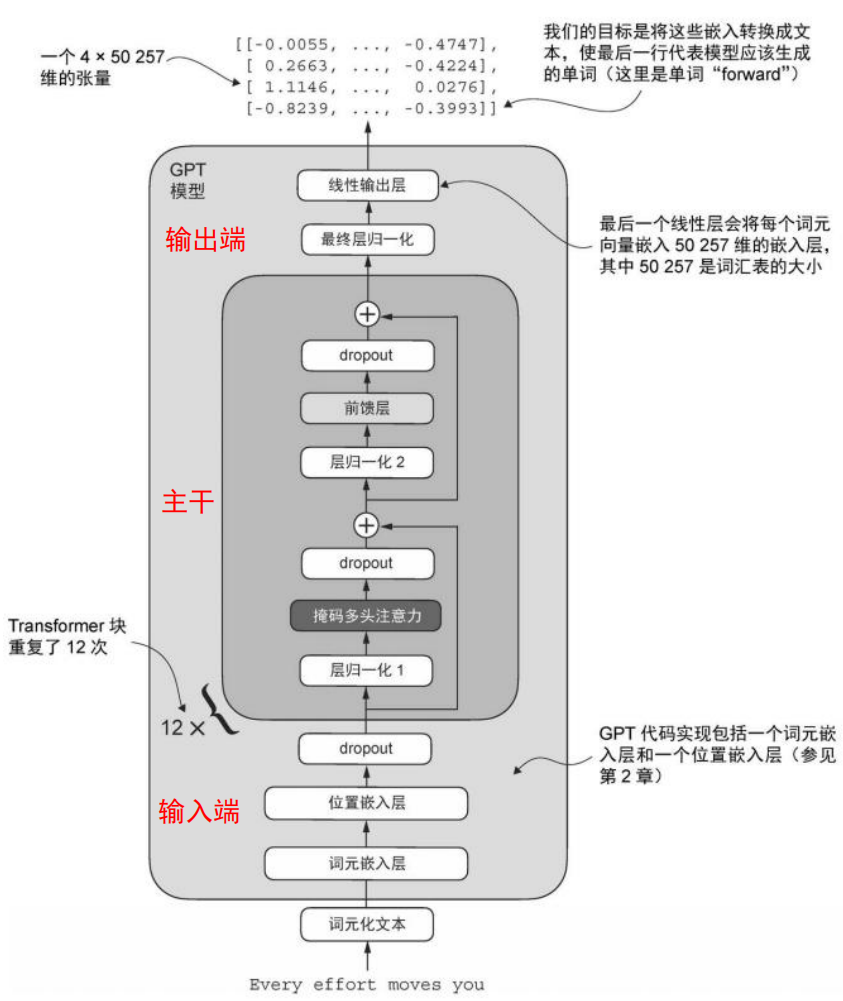
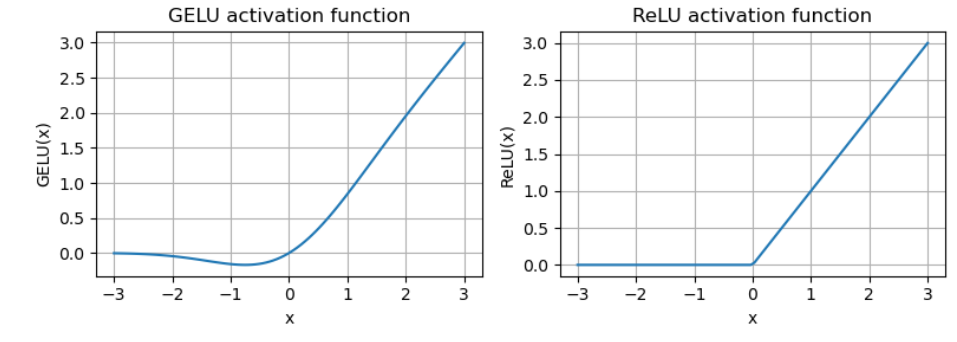
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
| import torch
import torch.nn as nn
import tiktoken
from torch.utils.data import Dataset, DataLoader
"""
GPTModel
"""
class GPTModel(nn.Module):
"""
一个可用的 GPT 模型骨架:
Token Embedding + Position Embedding
-> 多层 TransformerBlock 堆叠
-> 最终 LayerNorm
-> 输出头(投影回词表大小,得到 logits)
"""
def __init__(self,cfg):
super().__init__()
self.tok_emb=nn.Embedding(cfg["vocab_size"],cfg["emb_dim"])
self.pos_emb=nn.Embedding(cfg["context_length"],cfg["emb_dim"])
self.drop_emb=nn.Dropout(cfg["drop_rate"])
self.trf_blocks=nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm=LayerNorm(cfg["emb_dim"])
self.out_head=nn.Linear(
cfg["emb_dim"],cfg["vocab_size"],bias=False
)
def forward(self,in_idx):
"""
前向传播:
in_idx: (batch_size, seq_len) 的 token id
返回:
logits: (batch_size, seq_len, vocab_size)
表示每个位置对词表中所有 token 的预测打分
"""
batch_size,seq_len=in_idx.shape
tok_embeds=self.tok_emb(in_idx)
pos_embeds=self.pos_emb(torch.arange(seq_len,device=in_idx.device))
x=tok_embeds+pos_embeds
x=self.drop_emb(x)
x=self.trf_blocks(x)
x=self.final_norm(x)
logits=self.out_head(x)
return logits
def forward(self,in_idx):
batch_size,seq_len=in_idx.shape
tok_embeds=self.tok_emb(in_idx)
pos_embeds=self.pos_emb(torch.arange(seq_len,device=in_idx.device))
x=tok_embeds+pos_embeds
x=self.drop_emb(x)
x=self.trf_blocks(x)
x=self.final_norm(x)
logits=self.out_head(x)
return logits
"""
TransformerBlock
"""
class TransformerBlock(nn.Module):
def __init__(self,cfg):
super().__init__()
self.att=MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff=FeedForward(cfg)
self.norm1=LayerNorm(cfg["emb_dim"])
self.norm2=LayerNorm(cfg["emb_dim"])
self.drop_shortcut=nn.Dropout(cfg["drop_rate"])
def forward(self,x):
shortcut=x
x=self.norm1(x)
x=self.att(x)
x=self.drop_shortcut(x)
x=x+shortcut
shortcut=x
x=self.norm2(x)
x=self.ff(x)
x=self.drop_shortcut(x)
x=x+shortcut
return x
"""
LayerNorm
"""
class LayerNorm(nn.Module):
"""
1. 对每个样本在特征维度上标准化
2. 用两个可学习参数把标准化后结果:缩放和平移
- eps:很小的常熟,用于后续计算时避免除零
- scale:缩放
- shift:平移
"""
def __init__(self,emb_dim):
super().__init__()
self.eps=1e-5
self.scale=nn.Parameter(torch.ones(emb_dim))
self.shift=nn.Parameter(torch.zeros(emb_dim))
def forward(self,x):
mean=x.mean(dim=-1,keepdim=True)
var=x.var(dim=-1,keepdim=True)
norm_x=(x-mean)/torch.sqrt(var+self.eps)
return self.scale * norm_x + self.shift
"""
GRLU
"""
class GELU(nn.Module):
"""
具有GRLU激活函数的前馈神经网络
- 传统的ReLU
* - GELU:融合了高斯分布相关的平滑非线性(在负值区间保留非零梯度)
- SwiGLU:引入了基于sigmoid的门控机制
"""
def __init__(self):
super().__init__()
def forward(self,x):
"""
tanh 近似公式:
GELU(x) ≈ 0.5 * x * (1 + tanh( sqrt(2/pi) * (x + 0.044715 * x^3) ))
其中 0.044715 是经验常数,sqrt(2/pi) 是缩放系数
"""
return 0.5*x*(1+torch.tanh(
torch.sqrt(torch.tensor(2.0/torch.pi))*
(x+0.044715*torch.pow(x,3))
))
"""
FeedForward
"""
class FeedForward(nn.Module):
"""
Sequential:
按顺序把多个层串起来,前一层的输出自动作为下一层的输入
不用的话,需要自己写:
layer1 = nn.Linear(10, 20)
layer2 = nn.ReLU()
layer3 = nn.Linear(20, 5)
def forward(self, x):
x = layer1(x)
x = layer2(x)
x = layer3(x)
return x
"""
def __init__(self,cfg):
super().__init__()
self.layers=nn.Sequential(
nn.Linear(cfg["emb_dim"],4*cfg["emb_dim"]),
GELU(),
nn.Linear(4*cfg["emb_dim"],cfg["emb_dim"]),
)
def forward(self,x):
return self.layers(x)
"""
掩码多头注意力机制
"""
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader_v1(txt, batch_size=4, max_length=256,
stride=128, shuffle=True, drop_last=True, num_workers=0):
tokenizer = tiktoken.get_encoding("gpt2")
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
dataloader = DataLoader(
dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=num_workers)
return dataloader
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
attn_scores = queries @ keys.transpose(2, 3)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
context_vec = (attn_weights @ values).transpose(1, 2)
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec)
return context_vec
"""
生成文本函数
"""
def generate_text_simple(model,idx,max_new_tokens,context_size):
"""
使用“贪心解码(greedy decoding)”生成文本的简化函数。
参数:
- model: 已构建好的 GPT 模型,输入 token id 序列,输出每个位置的 logits
- idx: 初始上下文的 token id,形状 (batch_size, seq_len)
- max_new_tokens: 要生成的新 token 数量
- context_size: 模型允许的最大上下文长度(超出时只截取最后 context_size 个 token)
"""
for _ in range(max_new_tokens):
idx_cond=idx[:,-context_size:]
with torch.no_grad():
logits=model(idx_cond)
logits=logits[:,-1,:]
probas=torch.softmax(logits,dim=-1)
idx_next=torch.argmax(probas,dim=-1,keepdim=True)
idx=torch.cat((idx,idx_next),dim=1)
return idx
|