文本数据处理
终于结束了考研,现在重新拾起我的博客,记录学习。
LLM学习
基础阶段决定先根据:张梅山老师发布的大模型基础学习路线
特此感谢!
笔记只记录一些关键代码,方便后续回顾复盘
文本数据处理
过程
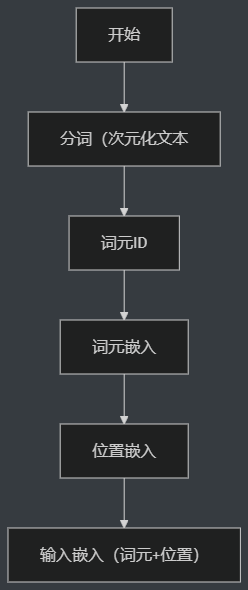
- 分词(encode)
- **标准化:**读取文本,处理标点符号
- **拆分 (Split):**使用 正则表达式将文本切分为列表
- **去重与排序:**提取所有唯一的单词
- **构建映射表:**词 —— ID
- 反过来(decode)
输入文本
1
2
3
4
5
| with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
|
词元化文本(分词)
分词(tokenize)后嵌入(embedding)
分词:用正规表达式来进行分割为词元(token)—> 构建一个词表
词元ID
嵌入:文本(token)转换成对应的数字编号(token ID)
后续嵌入层(embedding layer)进行处理得到向量表示
1
2
3
4
5
6
7
8
|
all_words = sorted(set(preprocessed))
vocab = {token:integer for integer, token in enumerate(all_words)}
int_to_str = {i:s for s,i in vocab.items()}
|
特殊词元:未知词和文本结束的位置
最终获取ID
1
2
3
4
5
6
7
8
|
all_tokens = sorted(list(set(preprocessed)))
all_tokens.extend(["<|endoftext|>","<|unk|>"])
vocab = {token:integer for integer,token in enumerate(all_tokens)}
|
分词器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| class SimpleTokenizerV2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self,text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)',text)
preprocessed = [
item.strip() for item in preprocessed if item.strip()
]
preprocessed = [item if item in self.str_to_int
else "<|unk|>" for item in preprocessed]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
text = re.sub(r'\s+([,.:;?!"()\'])',r'\1',text)
return text
|
使用分词器
1
2
3
4
5
6
7
8
|
tokenizer = SimpleTokenizerV2(vocab)
tokenizer.encode(text)
tokenizer.decode(tokenizer.encode(text))
|
BPE分词
BPE(Byte Pair Encoding,字节对编码):把不在词表的单词拆成更小的子词单元,处理词表外词
1
2
3
4
5
| import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
|
使用滑动窗口进行数据采样
按顺序一次生成一个词(token)

数据加载器,遍历输入数据集,返回序列:输入序列,向右平移一位后的目标序列
顺序:
- 样本的输入序列、目标序列
- 文本编码为ID
- 滑动窗口取片段,当前窗口的输入序列、目标序列
- 将 3 转为张量保存到 1 里面
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| import torch
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
token_ids = tokenizer.encode(txt)
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
|
张量 表示多维数组,用tensor(喂给神经网络)不用list的原因:
1. 计算速度更快
2. 可以放到GPU跑
3. 支持自动求导
DataLoader
PyTorch里面专门负责喂数据给模型的工具:它负责把数据集按批次、一组一组地送给模型训练
参数情况:
- batch_size:一次给大模型喂几个样本,一次训练输入4条序列
- max_length:每个样本序列长度,每个输入样本有256个token
- stride:滑动窗口步长
- =1:最大化数据利用率,但计算量大,数据高度重叠
- =Context Length:可能丢失跨边界的语义
- 最佳实践:通常 Stride 设置这就等于 Context Length 以避免过拟合,但在数据稀缺时可减小 Stride
常见设置:stride < max_length,为了重叠,使得上下文具有连续性
- shuffle:训练时为True,测试时为False
- drop_last:最后不满 batch_size 的 batch 是否丢掉,统一shape
- num_workers:用几个子进程加载数据,=0 主进程,多个常用于数据量大的时候
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def create_dataloader_v1(txt, batch_size=4, max_length=256, stride=128,
shuffle=True, drop_last=True, num_workers=0):
tokenizer = tiktoken.get_encoding("gpt2")
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
dataloader = DataLoader(dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last,
num_workers=num_workers)
return dataloader
|
使用
1
2
3
4
5
6
7
8
9
10
| dataloader = create_dataloader_v1(
raw_text, batch_size=1, max_length=4, stride=4, shuffle=False
)
data_iter = iter(dataloader)
first_batch = next(data_iter)
inputs, targets = next(data_iter)
|
注意:stride可以设置更大一些,不同样本尽量不要重叠,重叠使得训练数据过于相似,增加过拟合风险
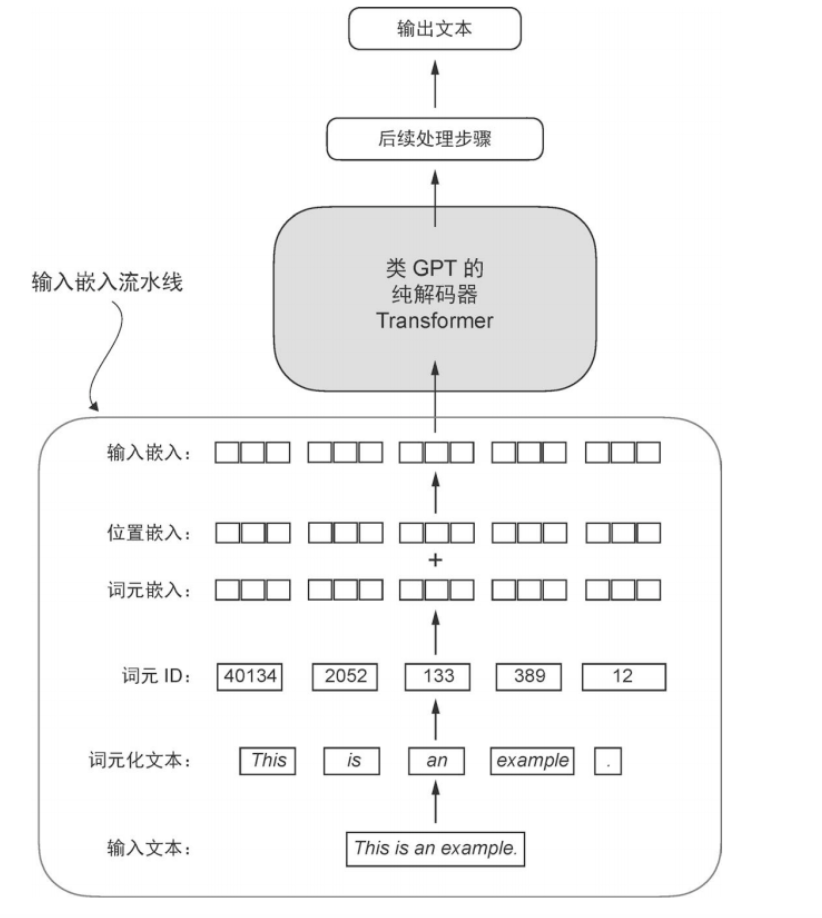
词元嵌入
可训练的查找表:ID通过嵌入层转换成连续的向量表示,要设置每个词的嵌入向量维度
表示是什么词,给定一个Token ID,层直接返回对应的行向量
embedding_layer = torch.nn.Embedding(vocab_size,output_dim)
嵌入层:看作“查表用”的权重矩阵,形状=词表词数(ID取值范围)× 嵌入向量维度
也就是6行对应词表中的6个token,每一行是一个长度为3的嵌入向量(token用三个数字表示)
嵌入向量维度:表示特征
嵌入层等价于“one-hot加矩阵乘法”
1
2
3
4
5
6
7
8
9
10
|
vocab_size = 50257
output_dim = 256
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
token_embeddings = token_embedding_layer(inputs)
token_embeddings.shape
|
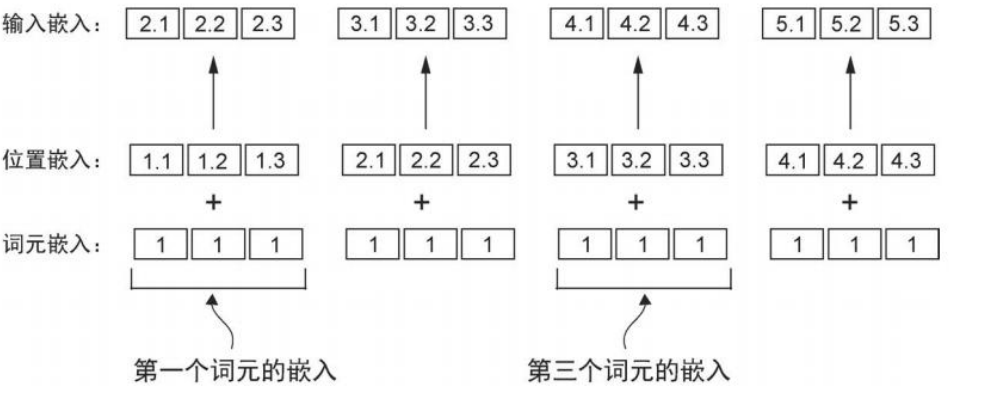
位置嵌入
gpt-2 使用绝对位置嵌入,为序列每一个位置分配一个固定的“位置编号”,编号通过嵌入层映射为向量。
告知在哪个位置,谁在前,谁在后。
每个位置也有自己的向量
1
2
3
4
5
6
7
8
| context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
pos_embeddings = pos_embedding_layer(torch.arange(context_length))
|
输入嵌入
位置嵌入与token的嵌入向量结合
1
| input_embeddings = token_embeddings + pos_embeddings
|